
Implementing SQLAlchemy in FastAPI
First you need to install SQLAlchemy:
pip install sqlalchemy
When using PyCharm you can also right-click to install it when you are first importing it in a .py-file.
For these examples, let's say you have a directory called myproject with a structure like this:
📂myproject
├── 📄__init__.py
├── 📄main.py
├── 📄database.py
├── 📄models.py
├── 📄schemas.py
└── 📄crud.py
- 📄
__init__.py: just an empty file, but it tells Python thatmyprojectwith all its modules (Python files) is a package. - 📄
main.py: the usual FastAPI main application file. - 📄
database.py: holds the database URL and db connection session creation. - 📄
models.py: holds the SQLAlchemy models that will describe the entities. - 📄
schemas.py: holds the Pydantic schema classes as we used before, and that use the SQLAlchemy models. - 📄
crud.py: holds the functions that will do Create, Read, Update and Delete operations and queries on the database.
Now let's see what each file/module does.
📄 Database.py file
Let's refer to the file database.py.
Import the SQLAlchemy parts:
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
Create a database URL for SQLAlchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
SQLALCHEMY_DATABASE_URL = "sqlite:///./sqlitedb/sqlitedata.db"
# SQLALCHEMY_DATABASE_URL = "postgresql://user:password@postgresserver/db"
In this example, we are "connecting" to a SQLite database (opening a file with the SQLite database). The file will be located at the sqlitedb directory in the file sqlitedata.db. This file will be automatically created at startup. However, the containing folder will not be created at startup. We will fix that later in the main.py-file.
If you were using a PostgreSQL database instead, you would just have to uncomment the line:
SQLALCHEMY_DATABASE_URL = "postgresql://user:password@postgresserver/db"
...and adapt it with your database data and credentials (equivalently for MySQL, MariaDB or any other).
Tips
This is the main line that you would have to modify if you wanted to use a different database.
Create the SQLAlchemy engine
The first step is to create a SQLAlchemy "engine".
We will later use this engine in other places.
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
SQLALCHEMY_DATABASE_URL = "sqlite:///./sqlitedb/sqlitedata.db"
# SQLALCHEMY_DATABASE_URL = "postgresql://user:password@postgresserver/db"
engine = create_engine(
SQLALCHEMY_DATABASE_URL, connect_args={"check_same_thread": False}
)
The argument:
connect_args={"check_same_thread": False}
...is needed only for SQLite. It's not needed for other databases.
"Technical Details"
By default SQLite will only allow one thread to communicate with it, assuming that each thread would handle an independent request.
This is to prevent accidentally sharing the same connection for different things (for different requests).
But in FastAPI, using normal functions (def), more than one thread could interact with the database for the same request, so we need to let SQLite know that it should allow that with connect_args={"check_same_thread": False}.
Also, we will make sure each request gets its own database connection session in a dependency, so there's no need for that default mechanism.
Create a SessionLocal class
Each instance of the SessionLocal class will be a database session. The class itself is not a database session yet.
But once we create an instance of the SessionLocal class, this instance will be the actual database session.
We name it SessionLocal to distinguish it from the Session we are importing from SQLAlchemy.
We will use Session (the one imported from SQLAlchemy) later.
To create the SessionLocal class, use the function sessionmaker:
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
SQLALCHEMY_DATABASE_URL = "sqlite:///./sqlitedb/sqlitedata.db"
# SQLALCHEMY_DATABASE_URL = "postgresql://user:password@postgresserver/db"
engine = create_engine(
SQLALCHEMY_DATABASE_URL, connect_args={"check_same_thread": False}
)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Info
More information about the parameters of the sessionmaker function can be found in the documentation of SQLAlchemy.
Create a Base class
Now we will use the function declarative_base() that returns a class.
Later we will inherit from this class to create each of the database models or classes (the ORM models):
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
SQLALCHEMY_DATABASE_URL = "sqlite:///./sqlitedb/sqlitedata.db"
# SQLALCHEMY_DATABASE_URL = "postgresql://user:password@postgresserver/db"
engine = create_engine(
SQLALCHEMY_DATABASE_URL, connect_args={"check_same_thread": False}
)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base = declarative_base()
📄 Models.py file
Let's now see the file models.py.
Create SQLAlchemy models from the Base class
We will use this Base class we created before to create the SQLAlchemy models.
Tips
SQLAlchemy uses the term "model" to refer to these classes and instances that interact with the database.
But Pydantic also uses the term "model" to refer to something different, the data validation, conversion, and documentation classes and instances.
Import Base from database (the file database.py from above).
Create classes that inherit from it.
These classes are the SQLAlchemy models.
from database import Base
class User(Base):
__tablename__ = "users"
class Item(Base):
__tablename__ = "items"
The __tablename__ attribute tells SQLAlchemy the name of the table to use in the database for each of these models.
Create model attributes/columns
Now create all the model (class) attributes.
Each of these attributes represent a column in its corresponding database table.
We use Column from SQLAlchemy as the default value.
And we pass a SQLAlchemy class "type", as Integer, String, and Boolean, that defines the type in the database, as an argument.
from sqlalchemy import Boolean, Column, ForeignKey, Integer, String
from database import Base
class User(Base):
__tablename__ = "users"
id = Column(Integer, primary_key=True, index=True)
email = Column(String, unique=True, index=True)
hashed_password = Column(String)
is_active = Column(Boolean, default=True)
class Item(Base):
__tablename__ = "items"
id = Column(Integer, primary_key=True, index=True)
title = Column(String, index=True)
description = Column(String, index=True)
owner_id = Column(Integer, ForeignKey("users.id"))
Create the relationships
Now create the relationships.
For this, we use relationship provided by SQLAlchemy ORM.
This will become, more or less, a "magic" attribute that will contain the values from other tables related to this one.
from sqlalchemy import Boolean, Column, ForeignKey, Integer, String
from sqlalchemy.orm import relationship
from database import Base
class User(Base):
__tablename__ = "users"
id = Column(Integer, primary_key=True, index=True)
email = Column(String, unique=True, index=True)
hashed_password = Column(String)
is_active = Column(Boolean, default=True)
items = relationship("Item", back_populates="owner")
class Item(Base):
__tablename__ = "items"
id = Column(Integer, primary_key=True, index=True)
title = Column(String, index=True)
description = Column(String, index=True)
owner_id = Column(Integer, ForeignKey("users.id"))
owner = relationship("User", back_populates="items")
When accessing the attribute items in a User, as in my_user.items, it will have a list of Item SQLAlchemy models (from the items table) that have a foreign key pointing to this record in the users table.
When you access my_user.items, SQLAlchemy will actually go and fetch the items from the database in the items table and populate them here.
And when accessing the attribute owner in an Item, it will contain a User SQLAlchemy model from the users table. It will use the owner_id attribute/column with its foreign key to know which record to get from the users table.
📄 Schemas.py file
Now let's check the file schemas.py.
Tips
To avoid confusion between the SQLAlchemy models and the Pydantic models, we will have the file models.py with the SQLAlchemy models, and the file schemas.py with the Pydantic models.
These Pydantic models define more or less a "schema" (a valid data shape).
So this will help us to avoid confusion while using both.
Create initial Pydantic models / schemas
Create ItemBase and UserBase Pydantic models (or let's say "schemas") to hold the common attributes while creating or reading data. These will be the superclasses to inherit from when creating the classes used for creating data and the classes used for reading data.
from pydantic import BaseModel
class ItemBase(BaseModel):
title: str
description: str | None = None
class UserBase(BaseModel):
email: str
Create Pydantic models / schemas for Creating
And create an ItemCreate and UserCreate that inherit from them, plus any additional data (attributes) needed for creation.
The pass at ItemCreate indicates that the superclass is taken over without any changes.
At UserCreate we indicate that the user will also have a password when creating one. But for security, the password won't be in other Pydantic models, for example, it won't be sent from the API when reading a user, which we will implement next.
from pydantic import BaseModel
class ItemBase(BaseModel):
title: str
description: str | None = None
class ItemCreate(ItemBase):
pass
class UserBase(BaseModel):
email: str
class UserCreate(UserBase):
password: str
Create Pydantic models / schemas for Reading / returning
Now create Pydantic models (schemas) that will be used when reading data, when returning it from the API. These also inherit from ItemBase and UserBase, but add more attributes to it.
For example in Item, before creating an item, we don't know what will be the ID assigned to it, but when reading it (when returning it from the API) we will already know its ID.
The same way in User, when reading a user, we can now declare that items will contain the items that belong to this user. Not only the IDs of those items, but all the data that we defined in the Pydantic model for reading items: Item.
from pydantic import BaseModel
class ItemBase(BaseModel):
title: str
description: str | None = None
class ItemCreate(ItemBase):
pass
class Item(ItemBase):
id: int
owner_id: int
class UserBase(BaseModel):
email: str
class UserCreate(UserBase):
password: str
class User(UserBase):
id: int
is_active: bool
items: list[Item] = []
Tips
Notice that the User, the Pydantic model that will be used when reading a user (returning it from the API) doesn't include the password.
Use Pydantic's orm_mode
Now, in the Pydantic models for reading, Item and User, add an internal Config class. This Config class is used to provide configurations to Pydantic.
In the Config class, set the attribute orm_mode = True.
from pydantic import BaseModel
class ItemBase(BaseModel):
title: str
description: str | None = None
class ItemCreate(ItemBase):
pass
class Item(ItemBase):
id: int
owner_id: int
class Config:
orm_mode = True
class UserBase(BaseModel):
email: str
class UserCreate(UserBase):
password: str
class User(UserBase):
id: int
is_active: bool
items: list[Item] = []
class Config:
orm_mode = True
Note
Notice it's assigning a value with =, like: orm_mode = True
It doesn't use : as for the type declarations before.
This is setting a config value, not declaring a type.
Pydantic's orm_mode will tell the Pydantic model to read the data even if it is not a dict, but an ORM model (or any other arbitrary object with attributes).
This way, instead of only trying to get the id value from a dict, as in:
id = data["id"]
it will also try to get it from an attribute, as in:
id = data.id
And with this, the Pydantic model is compatible with ORMs, and you can just declare it in the response_model argument in your path operations.
You will be able to return a database model and it will read the data from it.
Technical Details about ORM mode
SQLAlchemy and many others are by default "lazy loading".
That means, for example, that they don't fetch the data for relationships from the database unless you try to access the attribute that would contain that data.
For example, accessing the attribute items:
current_user.items
would make SQLAlchemy go to the items table and get the items for this user, but not before.
Without orm_mode, if you returned a SQLAlchemy model from your path operation, it wouldn't include the relationship data.
Even if you declared those relationships in your Pydantic models.
But with ORM mode, as Pydantic itself will try to access the data it needs from attributes (instead of assuming a dict), you can declare the specific data you want to return and it will be able to go and get it, even from ORMs.
📄 Crud.py file
Now let's see the file crud.py.
In this file we will have reusable functions to interact with the data in the database.
CRUD comes from: Create, Read, Update, and Delete. Although in this example we are only creating and reading.
Read data
Import Session from sqlalchemy.orm, this will allow you to declare the type of the db parameters and have better type checks and completion in your functions.
Import models (the SQLAlchemy models) and schemas (the Pydantic models / schemas).
Create utility functions to:
- Read a single user by ID and by email.
- Read multiple users.
- Read multiple items.
from sqlalchemy.orm import Session
import models
import schemas
def get_user(db: Session, user_id: int):
return db.query(models.User).filter(models.User.id == user_id).first()
def get_user_by_email(db: Session, email: str):
return db.query(models.User).filter(models.User.email == email).first()
def get_users(db: Session, skip: int = 0, limit: int = 100):
return db.query(models.User).offset(skip).limit(limit).all()
def get_items(db: Session, skip: int = 0, limit: int = 100):
return db.query(models.Item).offset(skip).limit(limit).all()
Tips
By creating functions that are only dedicated to interacting with the database (get a user or an item) independent of your path operation function, you can more easily reuse them in multiple parts and also add unit tests for them.
Create data
Now create utility functions to create data.
The steps are:
- Create a SQLAlchemy model instance with your data.
addthat instance object to your database session.committhe changes to the database (so that they are saved).refreshyour instance (so that it contains any new data from the database, like the generated ID).
from sqlalchemy.orm import Session
import models
import schemas
def get_user(db: Session, user_id: int):
return db.query(models.User).filter(models.User.id == user_id).first()
def get_user_by_email(db: Session, email: str):
return db.query(models.User).filter(models.User.email == email).first()
def get_users(db: Session, skip: int = 0, limit: int = 100):
return db.query(models.User).offset(skip).limit(limit).all()
def create_user(db: Session, user: schemas.UserCreate):
fake_hashed_password = user.password + "notreallyhashed"
db_user = models.User(email=user.email, hashed_password=fake_hashed_password)
db.add(db_user)
db.commit()
db.refresh(db_user)
return db_user
def get_items(db: Session, skip: int = 0, limit: int = 100):
return db.query(models.Item).offset(skip).limit(limit).all()
def create_user_item(db: Session, item: schemas.ItemCreate, user_id: int):
db_item = models.Item(**item.dict(), owner_id=user_id)
db.add(db_item)
db.commit()
db.refresh(db_item)
return db_item
Tips
The SQLAlchemy model for User contains a hashed_password that should contain a secure hashed version of the password.
But as what the API client provides is the original password, you need to extract it and generate the hashed password in your application. And then pass the hashed_password argument with the value to save.
This example is of course not secure as the password is not actually hashed.
Passing dictionary values: Item(**item.dict())
Instead of passing each of the keyword arguments to Item and reading each one of them from the Pydantic model, we are generating a dict with the Pydantic model's data with:
item.dict()
and then we are passing the dict's key-value pairs as the keyword arguments to the SQLAlchemy Item, with:
Item(**item.dict())
And then we pass the extra keyword argument owner_id that is not provided by the Pydantic model, with:
Item(**item.dict(), owner_id=user_id)
📄 Main.py file
And now in the file main.py let's integrate and use all the other parts we created before.
Create the database tables
First import all the needed .py-files we created before. Then create the database tables if they do not exist yet by using the create_all() function based on the Base models we created earlier and bind it to our database engine.
At this point we also import os and use it to create the folder where our sqlitedata.db-file will be placed in. When the folder already exists we do nothing:
from fastapi import Depends, FastAPI, HTTPException
from sqlalchemy.orm import Session
import crud
import models
import schemas
from database import SessionLocal, engine
import os
if not os.path.exists('.\sqlitedb'):
os.makedirs('.\sqlitedb')
#"sqlite:///./sqlitedb/sqlitedata.db"
models.Base.metadata.create_all(bind=engine)
app = FastAPI()
Database migrations when changing entities
Normally you would probably initialize your database (create tables, etc) with Alembic. And you would also use Alembic for "migrations" which is its main job.
A "migration" is the set of steps needed whenever you change the structure of your SQLAlchemy models, add a new attribute, etc. to replicate those changes in the database, add a new column, a new table, etc.
You can find an example of Alembic in a FastAPI project in the templates from Project Generation - Template. Specifically in the alembic directory in the source code.
Create a dependency
Now use the SessionLocal class we created in the database.py file to create a dependency.
We need to have an independent database session/connection (SessionLocal) per request, use the same session through all the request and then close it after the request is finished.
And then a new session will be created for the next request.
For that, we will create a new dependency with yield. For more info on yield as Python syntax, refer to Dependencies with yield.
Our dependency will create a new SQLAlchemy SessionLocal that will be used in a single request, and then close it once the request is finished.
from fastapi import Depends, FastAPI, HTTPException
from sqlalchemy.orm import Session
import crud
import models
import schemas
from database import SessionLocal, engine
import os
if not os.path.exists('.\sqlitedb'):
os.makedirs('.\sqlitedb')
#"sqlite:///./sqlitedb/sqlitedata.db"
models.Base.metadata.create_all(bind=engine)
app = FastAPI()
# Dependency
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()
Info
We put the creation of the SessionLocal() and handling of the requests in a try block.
And then we close it in the finally block.
This way we make sure the database session is always closed after the request. Even if there was an exception while processing the request.
But you can't raise another exception from the exit code (after yield). See more in Dependencies with yield and HTTPException.
And then, when using the dependency in a path operation function, we declare it with the type Session we imported directly from SQLAlchemy.
This will then give us better editor support inside the path operation function, because the editor will know that the db parameter is of type Session:
from fastapi import Depends, FastAPI, HTTPException
from sqlalchemy.orm import Session
import crud
import models
import schemas
from database import SessionLocal, engine
import os
if not os.path.exists('.\sqlitedb'):
os.makedirs('.\sqlitedb')
#"sqlite:///./sqlitedb/sqlitedata.db"
models.Base.metadata.create_all(bind=engine)
app = FastAPI()
# Dependency
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()
@app.post("/users/", response_model=schemas.User)
def create_user(user: schemas.UserCreate, db: Session = Depends(get_db)):
@app.get("/users/", response_model=list[schemas.User])
def read_users(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
@app.get("/users/{user_id}", response_model=schemas.User)
def read_user(user_id: int, db: Session = Depends(get_db)):
@app.post("/users/{user_id}/items/", response_model=schemas.Item)
def create_item_for_user(
user_id: int, item: schemas.ItemCreate, db: Session = Depends(get_db)
):
@app.get("/items/", response_model=list[schemas.Item])
def read_items(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
Create your FastAPI path operations
Now, finally, here's the standard FastAPI path operations code.
from fastapi import Depends, FastAPI, HTTPException
from sqlalchemy.orm import Session
import crud
import models
import schemas
from database import SessionLocal, engine
import os
if not os.path.exists('.\sqlitedb'):
os.makedirs('.\sqlitedb')
#"sqlite:///./sqlitedb/sqlitedata.db"
models.Base.metadata.create_all(bind=engine)
app = FastAPI()
# Dependency
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()
@app.post("/users/", response_model=schemas.User)
def create_user(user: schemas.UserCreate, db: Session = Depends(get_db)):
db_user = crud.get_user_by_email(db, email=user.email)
if db_user:
raise HTTPException(status_code=400, detail="Email already registered")
return crud.create_user(db=db, user=user)
@app.get("/users/", response_model=list[schemas.User])
def read_users(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
users = crud.get_users(db, skip=skip, limit=limit)
return users
@app.get("/users/{user_id}", response_model=schemas.User)
def read_user(user_id: int, db: Session = Depends(get_db)):
db_user = crud.get_user(db, user_id=user_id)
if db_user is None:
raise HTTPException(status_code=404, detail="User not found")
return db_user
@app.post("/users/{user_id}/items/", response_model=schemas.Item)
def create_item_for_user(
user_id: int, item: schemas.ItemCreate, db: Session = Depends(get_db)
):
return crud.create_user_item(db=db, item=item, user_id=user_id)
@app.get("/items/", response_model=list[schemas.Item])
def read_items(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
items = crud.get_items(db, skip=skip, limit=limit)
return items
We are creating the database session before each request in the dependency with yield, and then closing it afterwards.
And then we can create the required dependency in the path operation function, to get that session directly.
With that, we can just call crud.get_user directly from inside of the path operation function and use that session.
About def vs async def
Here we are using SQLAlchemy code inside of the path operation function and in the dependency, and, in turn, it will go and communicate with an external database.
That could potentially require some "waiting".
But as SQLAlchemy doesn't have compatibility for using await directly, as would be with something like:
user = await db.query(User).first()
...and instead we are using:
user = db.query(User).first()
Then we should declare the path operation functions and the dependency without async def, just with a normal def, as:
@app.get("/users/{user_id}", response_model=schemas.User)
def read_user(user_id: int, db: Session = Depends(get_db)):
db_user = crud.get_user(db, user_id=user_id)
...
Info
If you need to connect to your relational database asynchronously, see Async SQL (Relational) Databases.
Try it out
You can copy this code and use it as is.
📂myproject
├── 📄__init__.py
├── 📄main.py
├── 📄database.py
├── 📄models.py
├── 📄schemas.py
└── 📄crud.py
Then you can run it with Uvicorn:
uvicorn myproject.main:app --reload
And then, you can open your browser at http://localhost:8000/docs.
And you will be able to interact with your FastAPI application, reading data from a real database:
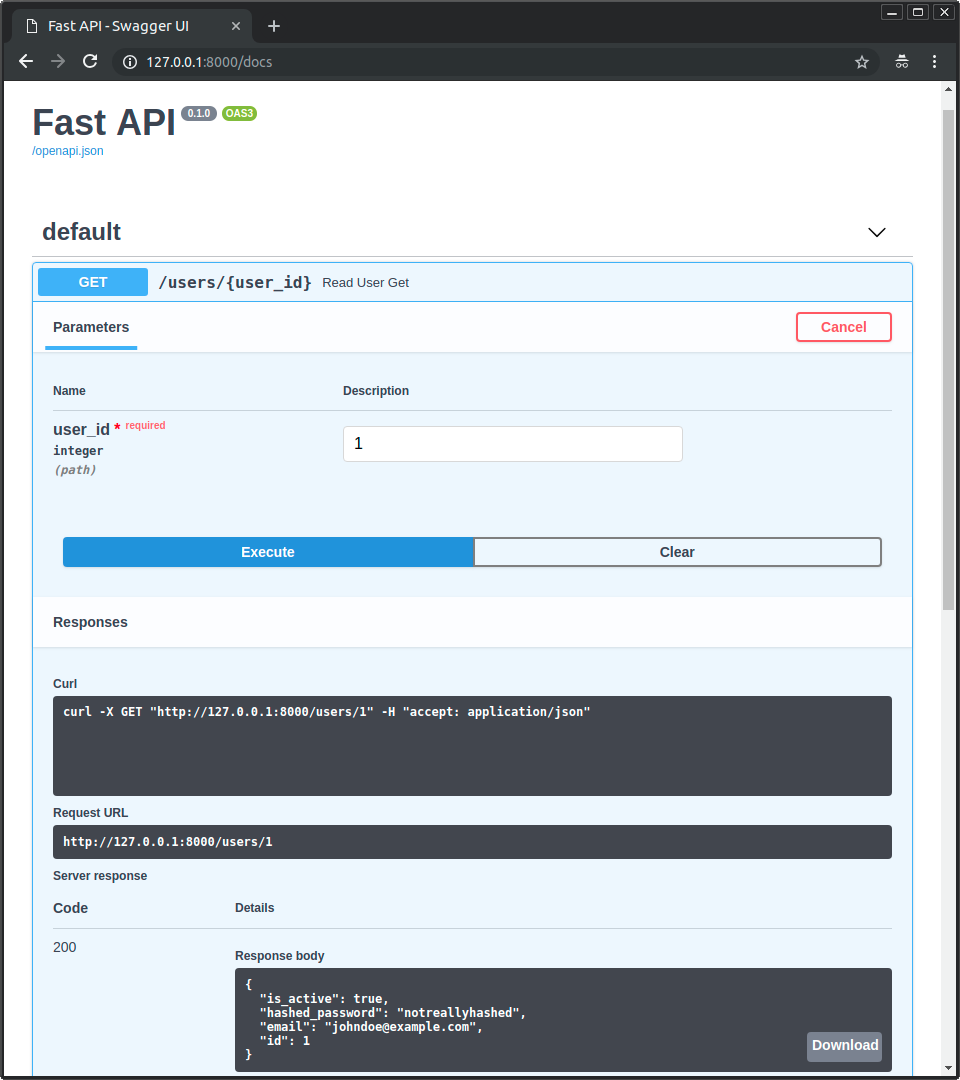
Interact with the database directly
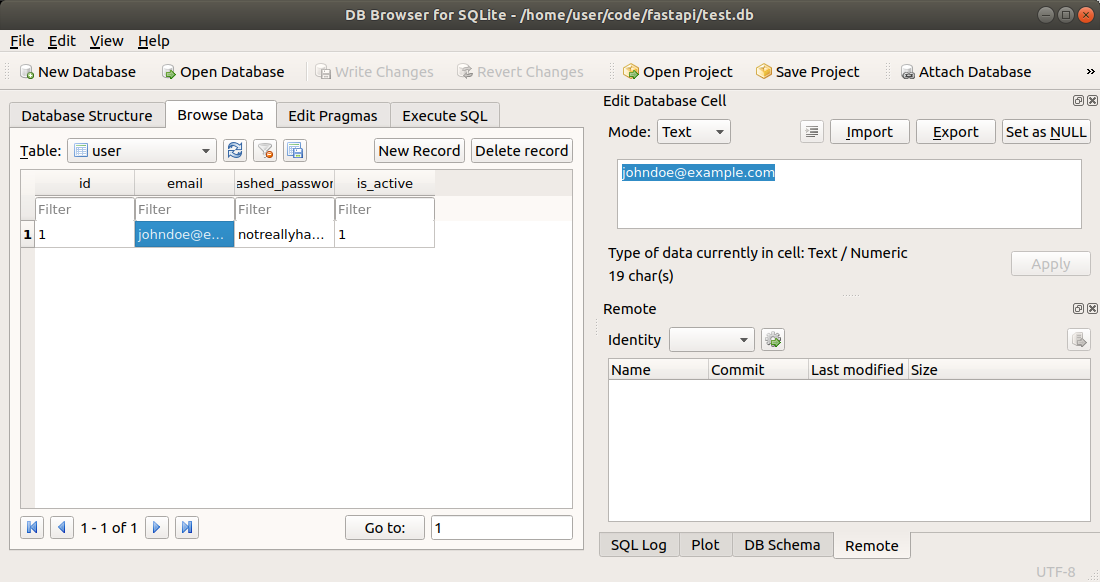
If you want to explore the SQLite database (file) directly, independently of FastAPI, to debug its contents, add tables, columns, records, modify data, etc. you can use DB Browser for SQLite.
It will look like this:
 You can also use an online SQLite browser like SQLite Viewer or ExtendsClass.
You can also use an online SQLite browser like SQLite Viewer or ExtendsClass.